AlphaGo Zeroの棋譜を鑑賞する、3日の学習で人類を超え21日でMastarを超えていく過程
ネットサーフィンをしていると
無視できない衝撃的なニュースが飛び込んできました。
囲碁AIが「独学」で最強に グーグル、産業応用探る :日本経済新聞
開発が終了したと思われていた
史上最強囲碁ソフトであるAlphaGoが
今度は一切外部の棋譜を使わない自己対戦のみで従来のAlphagoの実力を超えてしまったのです。
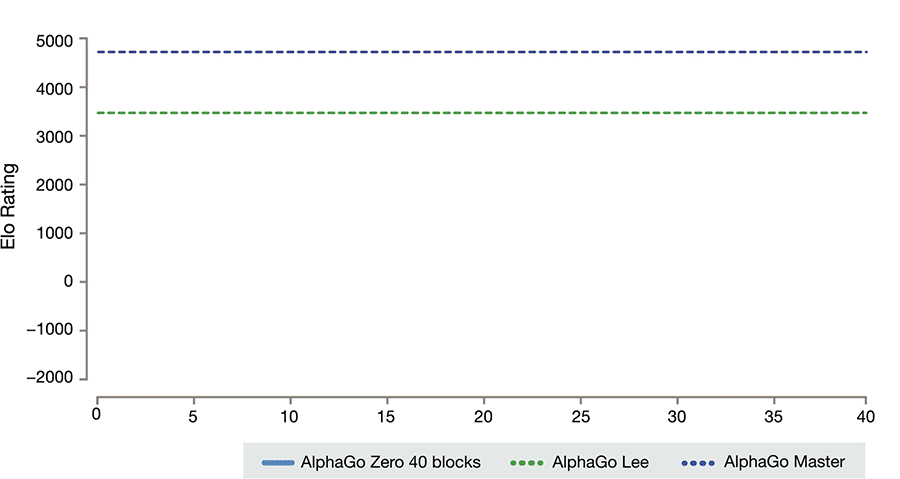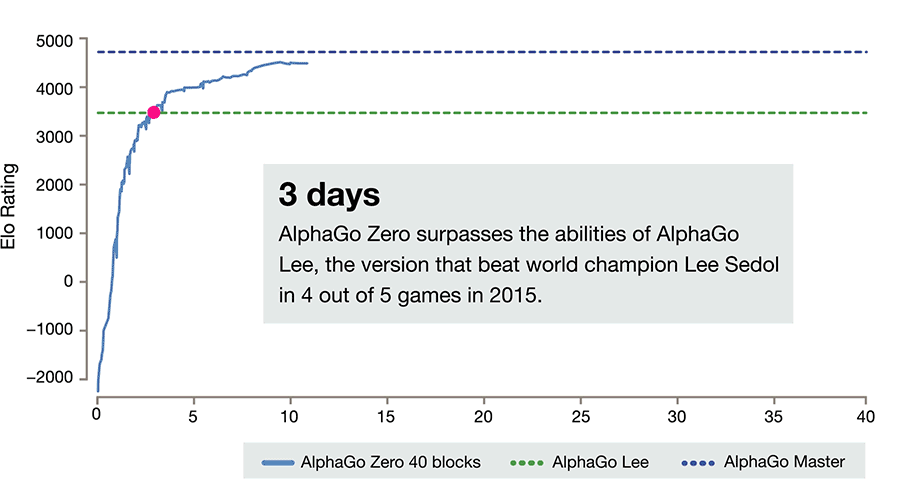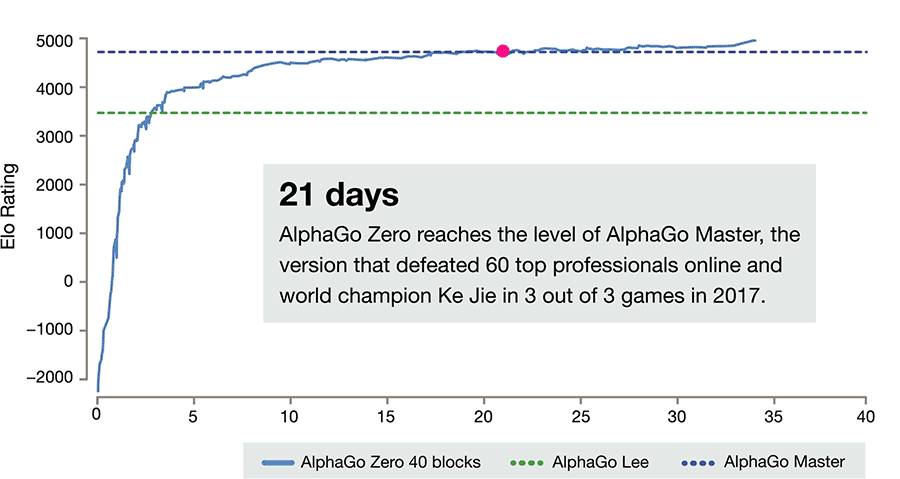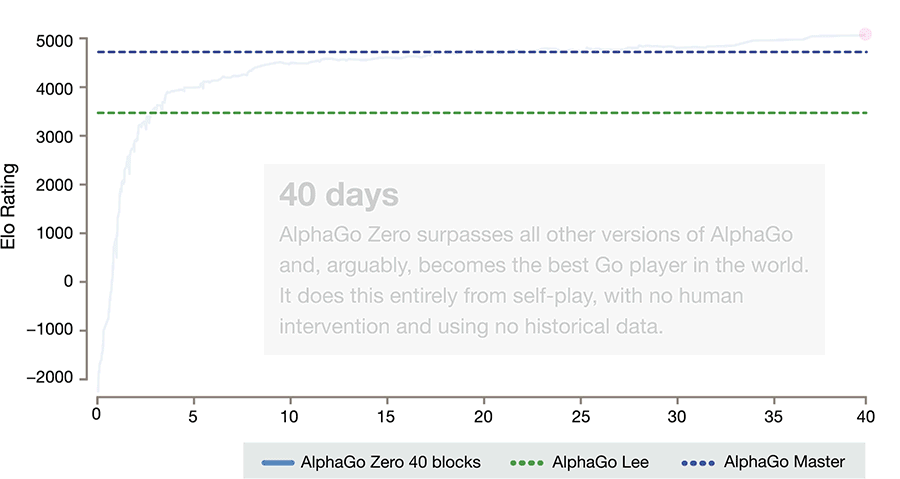
わずか3日の出来事
記事から引用します
当初はランダムに石を並べていたが、自己対戦を繰り返すことで急速に上達。実験3日後には、2016年3月にトップ棋士に勝った際のアルファ碁に100戦全勝をあげた。
なお、3日後に100戦全勝と書いてあるのは翻訳ミスでしょう。
実際にグラフを見ると、セドル氏と対戦したAlphaGoに追いつくのが3日ですので。
初期のAlphaGoはこの強さに到達するまでに半年の学習を必要としていました。
それもGooleが総力を挙げて取り組んでの半年間です。
当時の学習に用いた計算資源が少なかったという事は決してありません。
学習方法が大幅に進歩したという事です。
21日の学習でMastarを超える
AlphaGo Zeroの成長はまだ続きます。
学習の21日めには世界最強の囲碁棋士を破ったAlphago Masterに棋力で追いつきます。
囲碁の神様ではないかと言われるほど強かったMasterも
最終的には100戦でAlphaGo Zeroに89-11という手合違いの実力差にまで引き離されてしまいます。
最近のAIの学習方法の進歩は加速している印象ですね。
従来不可能と言われていた分野でも次々にAIが参入しては追い越していきました。
最近ですと確率ゲームのポーカーでもAIが人類に勝利したニュースが新しいですね。
きゅうり農家の方でも機械学習を元にきゅうりの仕分けをする時代ですし
もう人類が優位な点は殆どないのかもしれません。
人間の知識は足枷でしかない
DeepMind社の記事を読んでみましょう
AlphaGo Zero: Learning from scratch | DeepMind
This technique is more powerful than previous versions of AlphaGo because it is no longer constrained by the limits of human knowledge.
この技術は、もはや人間の知識の限界に制約されていないため、旧バージョンのAlphaGoよりも強力です。
えーと、はい。
人類の棋譜とか上を目指す際には邪魔だとハッキリ言っていますね。
学習方法も変わったようです
It uses one neural network rather than two. Earlier versions of AlphaGo used a “policy network” to select the next move to play and a ”value network” to predict the winner of the game from each position. These are combined in AlphaGo Zero, allowing it to be trained and evaluated more efficiently.
2つではなく1つのニューラルネットワークを使用します。 AlphaGoの以前のバージョンでは、「ポリシーネットワーク」を使用して次のプレイを選択し、「バリューネットワーク」を使用して各ポジションからゲームの勝者を予測しました。 これらはAlphaGo Zeroで結合され、より効率的に訓練され、評価されます。
従来のAlpha Goは2つの方式を同時並行して思考していましたが
今回のAlphaGo Zeroはそれらが統合され、より効率的な探索を実現してます。
そして衝撃的なのがこの文面
AlphaGo Zero does not use “rollouts” - fast, random games used by other Go programs to predict which player will win from the current board position. Instead, it relies on its high quality neural networks to evaluate positions.
AlphaGo Zeroは、他のGoプログラムが現在のボードポジションから勝つプレイヤーを予測するために使用される高速のランダムゲームである「ロールアウト」を使用しません。 代わりに、位置を評価するために高品質のニューラルネットワークに依存しています。
ロールアウト使わないんです!!
終局まで実際に打ってみて勝率を算出するのではく
AlphaGo Zeroはその局面情報から次の最善手を思考します。

(上図)急速に進化するAlphaGo Zero
学習開始から70時間で人間のトッププロクラスの棋力を身に着ける。
AlphaGo Zeroの棋譜を鑑賞しよう
さて、ここからはAlphaGo Zeroの棋譜を鑑賞していきます。
棋譜はネイチャーのサイトから無償でダウンロード可能です。
http://www.nature.com/nature/journal/v550/n7676/full/nature24270.html
学習最初期の自己対戦の棋譜
学習開始の頃のAlphaGo Zeroはランダムムーブです。
ここから史上最強ソフトに成長するとは・・・
(下図)学習最初期の棋譜10手目の段階

AlphaGoだから何か意図が・・・と深読みしたくなるが
この段階ではまだまだ弱いので深い意味はない。
(下図)学習最初期の棋譜50手目の段階

見事にバラバラで意図が見えない。
しかし笑うなかれ、人類を超えるAlphaGo Zeroにも初心者の時代はあるのだ。
学習初期の自己対戦の棋譜
前回よりほんの少し進んだ状態での棋譜
この段階ではまだまだ弱いが徐々にその学習能力の高さを見せ始める
(下図)学習初期の棋譜20手目

最初期と比べるとだんだん囲碁らしくなってきている。
勝ち方を把握し始めたか。
(下図)学習初期の棋譜60手目

先程の棋譜を60手目まで進めた局面
初期段階で早くも局地戦での戦い方を学習し始めたる。
学習中期の自己対戦の棋譜
中期になると打ち回しにも凄みが出てくる。
この段階で既にセドル氏と対戦したAlphaGoよりも強い。
(下図)学習中期の棋譜4手目

学習が進むとAlphaGo Zeroの4手目までの進行は全てこの局面になる。
更に学習が進むとまた違った序盤を見せるのだが、それは後述する。
(下図)学習中期の棋譜31手目

局地戦にはこだわらず、全体を見ながら石を打つ場所を決めているようだ。
学習末期の自己対戦の棋譜
ここからは人類未踏の領域
数ヶ月前に神の領域と言われたMasterに9割近く勝つ棋力に到達している。
(下図)学習末期の棋譜3手目

最序盤に早速変化が現れる。
これが現在の史上最も棋力の高い存在が導き出した序盤進行だ。
(下図)学習末期の棋譜40手目

盤面を広く使い始めた中期とは一転
再び局地戦を重視し始めたように見える。
(下図)学習末期の棋譜70手目

戦場と戦場が繋がり、AlphaGo Zeroの意図が徐々に明らかになってくる。
局地戦に見えた戦いは本格的な戦いへの下準備だった。
(下図)学習末期の棋譜130手目

これがAlphaGoの対局時の局面だと知らなければ意見が分かれそうだ。
gifアニメで棋譜を鑑賞しよう
最後のAlphago Zero vs Alphago Zeroの棋譜のGIFアニメーションを紹介して記事を終わりにする。

