Haskellで動的計画法 ナップサック問題を解く
Haskellでナップサック問題を解く時のメモ
ナップザック問題 | 動的計画法 | Aizu Online Judge
とりあえずAOJのこの問題で通るコードを目標にする。
まずは叩き台
{-# LANGUAGE FlexibleContexts #-} import Control.Applicative import Data.Array main = do [_,capa] <- map (read :: String -> Int) . words <$> getLine goods <- map (map (read :: String -> Int) . words) . lines <$> getContents print $ maximum $ elems (resolve capa (listArray (0,capa) [0,0..]) goods) resolve :: Int -> Array Int Int -> [[Int]] -> Array Int Int resolve capa capaArr ([v,w]:xs) | xs == [] = koushin capaArr [v,w] (capa-w) | otherwise = resolve capa (koushin capaArr [v,w] (capa-w)) xs where koushin :: Array Int Int -> [Int] -> Int -> Array Int Int koushin capaArr [v,w] n | n == 0 && capaArr ! w <= v = capaArr // [( w , v)] | n == 0 = capaArr | oldValue == 0 = next | capaArr ! (n+w) >= v + oldValue = next | otherwise = koushin (capaArr // [( n + w , v + oldValue)]) [v,w] (n-1) where oldValue = capaArr ! n next = koushin capaArr [v,w] (n-1)
叩き台として書いたのが上記のコード
main = do [_,capa] <- map (read :: String -> Int) . words <$> getLine goods <- map (map (read :: String -> Int) . words) . lines <$> getContents print $ maximum $ elems (resolve capa (listArray (0,capa) [0,0..]) goods)
入力を受け取る部分
容量をcapa、品物のリストをgoodsとして受取り
listArray (0,capa) [0,0..])
listArrayで、[(0,0),(1,0)・・・,(capa,0)]
までの配列を作ってresolve関数に送る。
resolve capa capaArr ([v,w]:xs) | xs == [] = koushin capaArr [v,w] (capa-w) | otherwise = resolve capa (koushin capaArr [v,w] (capa-w)) xs
resolve関数では品物1つ1つについて
koushin関数で配列を更新していく
原理については下の「最強最速アルゴリズマー養成講座」という記事が分かりやすい。(画像は下記サイトから)
病みつきになる「動的計画法」、その深淵に迫る (1/4) - ITmedia エンタープライズ
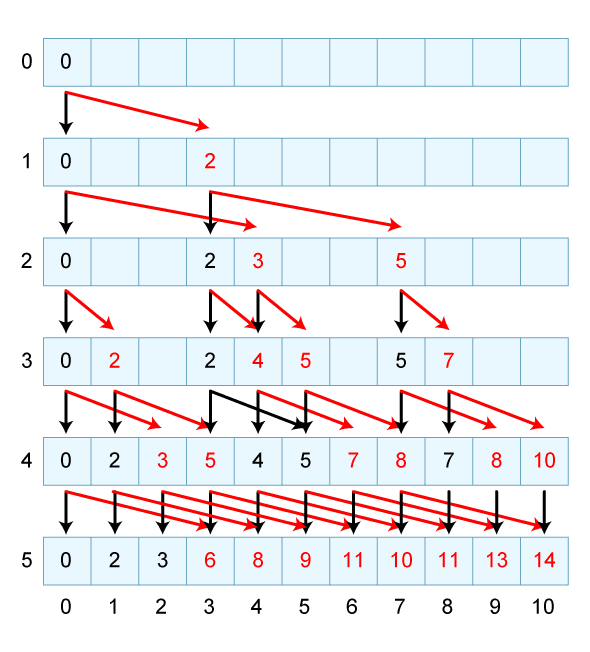
koushin capaArr [v,w] n | n == 0 && capaArr ! w <= v = capaArr // [( w , v)] | n == 0 = capaArr | oldValue == 0 = next | capaArr ! (n+w) >= v + oldValue = next | otherwise = koushin (capaArr // [( n + w , v + oldValue)]) [v,w] (n-1) where oldValue = capaArr ! n next = koushin capaArr [v,w] (n-1)
上記の画像のような配列の更新をしていく関数。
改善をしていく

このまま提出をすると遅すぎる&メモリを使いすぎるので通らなかった。
主に原因となっているのは
(//)が実は配列をまるごとコピーして再生成している事だろう。
Mapを使ってみる
{-# LANGUAGE FlexibleContexts #-} import Control.Applicative import qualified Data.Map.Strict as Map import Data.List (maximumBy) import Data.Ord (compare) import Data.Function (on) main = do [_,capa] <- map (read :: String -> Int) . words <$> getLine goods <- map (map (read :: String -> Int) . words) . lines <$> getContents print $ snd $ maximumBy (compare `on` snd) $ Map.toList (resolve capa (Map.fromList (zip [0..capa] [0,0..])) goods) resolve capa capaMap ([v,w]:xs) | xs == [] = koushin' | otherwise = resolve capa koushin' xs where koushin' = koushin capaMap [v,w] (capa-w) koushin capaMap [v,w] n | n == 0 && capaMap Map.! w <= v = Map.insert w v capaMap | n == 0 = capaMap | oldValue == 0 = next | capaMap Map.! (n+w) >= v + oldValue = next | otherwise = koushin (Map.insert (n+w) (v + oldValue) capaMap) [v,w] (n-1) where oldValue = capaMap Map.! n next = koushin capaMap [v,w] (n-1)
Data.Mapのinsert関数はO(log n)なので配列のコピーよりも高速。
とりあえず叩き台のコードを配列からMapに書き換えてみた。
maximumBy (compare `on` snd)
この部分はリストの中身にsnd関数を適用した値が最大の要素を抜き出す関数
そのせいでimportが大袈裟になってしまった。
普通に
maximum $ map snd
とした方が分かりやすかったか。
とりあえず上記のコードでもう一度提出してみると・・・

(やべっ通っちゃった)
通らないと思って提出したので
{-# LANGUAGE FlexibleContexts #-}
みたいな余計な文字まで入ってる有り様・・・
本当はTLEしてもっと頑張る予定だったのだけどまあいいか。
重複可のパターン
import Control.Applicative import qualified Data.HashMap.Strict as Map main = do [_,capa] <- map (read :: String -> Int) . words <$> getLine goods <- map (map (read :: String -> Int) . words) . lines <$> getContents print $ maximum $ map snd $ Map.toList (resolve capa (Map.fromList (zip [0..capa] [0,0..])) goods) resolve capa capaMap ([v,w]:xs) | xs == [] = koushin' | otherwise = resolve capa koushin' xs where koushin' = koushin capaMap [v,w] 0 koushin capaMap [v,w] n | n > (capa - w) = capaMap | n == 0 && capaMap Map.! w <= v = next' | capaMap Map.! (n+w) >= v + oldValue = next | otherwise = next' where oldValue = capaMap Map.! n next = koushin capaMap [v,w] (n+1) next' = koushin (Map.insert (n+w) (v + oldValue) capaMap) [v,w] (n+1)
先程のコードは簡単な改造で重複可のナップザック問題にも対応できる。
AOJには重複可のナップザック問題もあったので上記のコードで提出をしてみる。
Knapsack Problem | Aizu Online Judge
無事に通ってひと安心

Data.HashMap.Strictの方が通常のMap.Strictよりも高速。
HashMap.Strictだと00.25sだがMap.Strictだと00:46s
ここからが本題
まあ上記は当然ながら練習問題。
本番の問題はこちら
0-1 Knapsack Problem II | Aizu Online Judge
文章は冒頭の問題と同じだが
容量の範囲が10万倍、品物の重さの範囲も1万倍になっている。
同じようなコードで提出をしてみると
当然のようにTLE

更に高速なコードが必要となる。
ちなみにこの問題
執筆時点ではHaskellでパスした回答はゼロ件だった。

うん、頑張ろう。
Vectorを使ってみる
改善をしていく
import Control.Applicative import qualified Data.HashMap.Strict as Map main = do [_,capa] <- map (read :: String -> Int) . words <$> getLine goods <- map (map (read :: String -> Int) . words) . lines <$> getContents print $ maximum $ map snd $ Map.toList (resolve capa (Map.fromList (zip [0..capa] [0,0..])) goods) resolve capa capaMap ([v,w]:xs) | xs == [] = koushin' | otherwise = resolve capa koushin' xs where koushin' | capa < w = capaMap | otherwise = koushin capaMap [v,w] (capa-w) koushin capaMap [v,w] n | n == 0 && capaMap Map.! w <= v = Map.insert w v capaMap | n == 0 = capaMap | oldValue == 0 = next | capaMap Map.! (n+w) >= v + oldValue = next | otherwise = koushin (Map.insert (n+w) (v + oldValue) capaMap) [v,w] (n-1) where oldValue = capaMap Map.! n next = koushin capaMap [v,w] (n-1)
提出したコード
koushin capaMap [v,w] n
| n == 0 && capaMap Map.! w <= v = Map.insert w v capaMap
| n == 0 = capaMap
| oldValue == 0 = next
| capaMap Map.! (n+w) >= v + oldValue = next
| otherwise = koushin (Map.insert (n+w) (v + oldValue) capaMap) [v,w] (n-1)
おそらくマズいのはこの部分。
Map.insertを下手するとナップサックの容量回近く繰り返すコードになっている。
更新する項目をリストにしておいて一発で変更したほうが効率が良さそうだ。
となると今度はMap.!で値を参照するのに毎回O(log n)掛かるのが無駄なので
Vectorで書き直す事にした
新たな叩き台
import Control.Applicative import qualified Data.Vector.Unboxed as V main = do [_,capa] <- map (read :: String -> Int) . words <$> getLine goods <- map (map (read :: String -> Int) . words) . lines <$> getContents print $ V.maximum (resolve capa (V.enumFromStepN 0 0 (capa+1)) goods) resolve capa capaV ([v,w]:xs) | xs == [] = koushin' | otherwise = resolve capa koushin' xs where koushin' | capa < w = capaV | otherwise = koushin capaV [v,w] (capa-w) koushin capaV [v,w] n | n == 0 && capaV V.! w <= v = capaV V.// [( w , v)] | n == 0 = capaV | oldValue == 0 = next | capaV V.! (n+w) >= v + oldValue = next | otherwise = koushin (capaV V.// [( n + w , v + oldValue)]) [v,w] (n-1) where oldValue = capaV V.! n next = koushin capaV [v,w] (n-1)
さっそくここから修正していく
koushin'
| capa < w = capaV
| otherwise = koushin capaV [v,w] (capa-w) []
koushin capaV [v,w] n koushinList
| n == 0 && capaV V.! w <= v = capaV V.// ((w,v):koushinList)
| n == 0 = capaV V.// koushinList
| oldValue == 0 = next
| capaV V.! (n+w) >= v + oldValue = next
| otherwise = koushin capaV [v,w] (n-1) ((n + w, v + oldValue):koushinList)
where
oldValue = capaV V.! n
next = koushin capaV [v,w] (n-1) koushinList
koushinListに一度にまとめてから
最後に V.// koushinListを使いO(n)で処理するようにしてみた。
ローマ字かよという突っ込みが入りそうだが気にしない
早速再提出してみる。

でたー、MLE。
Haskellではお馴染み。
こうなると思い当たる方法はひとつしかない。
破壊的代入に挑戦
メモリや実行時間がカツカツの状況では
遅延評価だの再代入禁止だのと言っている暇はない。
さっそくIORefとVector.Mutableを使って
コードを書いてみた。
import Control.Applicative import Data.IORef import qualified Data.Vector.Mutable as VM main = do [_,capa] <- map (read :: String -> Int) . words <$> getLine goods <- map (map (read :: String -> Int) . words) . lines <$> getContents capaVM <- VM.replicate (capa+1) 0 ans <- newIORef 0 resolve capa capaVM goods ans print =<< readIORef ans resolve capa capaVM ([v,w]:xs) ans = if null xs then koushin' else do koushin' resolve capa capaVM xs ans where koushin' = if capa < w then return () else koushin [v,w] (capa-w) koushin [v,w] n = do oldValue <- VM.read capaVM n newValue <- VM.read capaVM (n+w) judge oldValue newValue where judge oldValue newValue | n == 0 && newValue <= v = next' | n ==0 = return () | newValue >= v + oldValue = next | otherwise = next'' where next = koushin [v,w] (n-1) next' = do VM.write capaVM (n+w) (v + oldValue) ans' <- readIORef ans writeIORef ans (max ans' (v + oldValue)) next'' = do next' koushin [v,w] (n-1)
・・・ツッコミどころは多いが
とりあえず動くものが出来上がったので提出してみる。

???
何故か前回のコードよりもメモリ消費が悪化している
Data.Vector.Unboxed.Mutableにしてもう一度提出。

これも駄目。
原因を探る
コードを眺めたところ
resolve capa capaVM ([v,w]:xs)
どうもこの辺りが怪しい。
そこでリストをVectorに変更して
処理の最中に大きなリストを使わないようにしてみた
import qualified Data.Vector as V main = do [kosuu,capa] <- map (read :: String -> Int) . words <$> getLine goods <- map (map (read :: String -> Int) . words) . lines <$> getContents let goodsV = V.fromList goods capaVM <- VM.replicate (capa+1) 0 ans <- newIORef 0 resolve capa capaVM goodsV ans 0 kosuu print =<< readIORef ans resolve capa capaVM goodsV ans n kosuu = if n == (kosuu- 1) then koushin' else do koushin' resolve capa capaVM goodsV ans (n+1) kosuu where koushin' = if capa < last (goodsV V.! n) then return () else koushin [(head (goodsV V.! n)),(last (goodsV V.! n))] (capa-(last (goodsV V.! n)))
最後のkoushin関数では
リストを使うが、要素2なのでなんとかなるだろう。
という訳で訂正したコードで再提出。

・・・駄目みたいですね。
もう一度原因を探る
どうも見当違いな場所を修正していたようなので
じっくりソースを眺めてもう一度メモリを使っているのはどの場所か精査してみた。
すると怪しいポイントを発見
koushin [v,w] n = do oldValue <- VM.read capaVM n newValue <- VM.read capaVM (n+w) judge oldValue newValue where judge oldValue newValue | n == 0 && newValue <= v = next' | n == 0 = return () | newValue >= v + oldValue = next | otherwise = next'' where next = koushin [v,w] (n-1) next' = do VM.write capaVM (n+w) (v + oldValue) ans' <- readIORef ans writeIORef ans (max ans' (v + oldValue)) next'' = do next' koushin [v,w] (n-1)
再帰してますねぇ・・・
秘密兵器mapM_
そこで再帰部分をmapM_を使って書き直す事にした。
わかりやすくする為にリストの方のコードをベースにする。
import Control.Applicative import Data.IORef import qualified Data.Vector.Mutable as VM import Control.Monad main = do [_,capa] <- map (read :: String -> Int) . words <$> getLine goods <- map (map (read :: String -> Int) . words) . lines <$> getContents capaVM <- VM.replicate (capa+1) 0 ans <- newIORef 0 mapM_ (resolve capa capaVM ans) goods print =<< readIORef ans resolve capa capaVM ans [v,w] = if capa < w then return () else mapM_ (koushin [v,w]) (reverse [0..(capa-w)]) where koushin [v,w] n = do oldValue <- VM.read capaVM n newValue <- VM.read capaVM (n+w) judge oldValue newValue where judge oldValue newValue | n == 0 && newValue <= v = kakikae | n ==0 = return () | newValue >= v + oldValue = return () | otherwise = kakikae where kakikae = do VM.write capaVM (n+w) (v + oldValue) ans' <- readIORef ans writeIORef ans (max ans' (v + oldValue))
だいぶコードがスッキリした。
mapM_ (koushin [v,w]) (reverse [0..(capa-w)])
このコードの意味は
仮に(capa-w)が2だとすると
koushin [v,w] 2
koushin [v,w] 1
koushin [v,w] 0
と順番に処理せよという意味。
resolveも同様に書き換えて再帰を排除(多分)
今度こそ行けるだろうと再提出をしてみた・・・

ぐはっ!!
またまた原因を探る
方向性は間違っていたようだが
コードが読みやすくなり修正の労力は低減された。
次に狙いを定めたのはこの部分
else mapM_ (koushin [v,w]) (reverse [0..(capa-w)])
[0..(capa-w)]が少々あやしい気がする。
この問題ではcapa = 1,000,000,000まで与えられるので
毎回生成をしていたらメモリの消費が半端ではない。
参照するコストも大きいだろう。
・・・という訳でひとまずここをVector.Unboxedにする事にした。
else V.mapM_ (koushin [v,w]) (V.enumFromStepN (capa-w) (-1) (capa-w+1))
> V.enumFromStepN 1 (-1) 5 [1,0,-1,-2,-3]
そして再提出。

えぇ・・・
根本的に間違えていた
途方に暮れて色々と調べてみると
どうもナップサック問題はナップサックの容量が巨大な時には
価値をベースにしてプログラムを組むらしい。
という訳で
初期のMapを使ったコードをベースに書き直してみた。
import Control.Applicative import qualified Data.IntMap.Strict as Map import Data.List (sort) main = do [_,capa] <- map (read :: String -> Int) . words <$> getLine goods <-map (map (read :: String -> Int) . words) . lines <$> getContents let maxValue = foldl1 (+) $ map head goods let ans = resolve capa maxValue (Map.fromList (zip [0..maxValue] [0,0..])) (reverse (sort goods)) print $ if Map.null ans then 0 else fst $ Map.findMax ans resolve capa maxValue valueMap ([v,w]:xs) | xs == [] = Map.filter (>0) koushin' | otherwise = resolve capa maxValue koushin' xs where koushin' | capa < w = valueMap | otherwise = koushin valueMap [v,w] (maxValue-v) koushin valueMap [v,w] n | n == 0 && valueMap Map.! v > w = Map.insert v w valueMap | n == 0 && oldWight == 0 = Map.insert v w valueMap | n == 0 = valueMap | oldWight == 0 = next | w + oldWight > capa = next | (w + oldWight >= newWight) && newWight /= 0 = next | otherwise = koushin (Map.insert (n+v) (w + oldWight) valueMap) [v,w] (n-1) where oldWight = valueMap Map.! n newWight =valueMap Map.! (n+v) next = koushin valueMap [v,w] (n-1)
価値の高い順にソートしてから処理しているのがポイント。
提出してみる。


通った!!
処理の方法でこんなにも違うとはビックリ。
回り道はしたけども勉強になった。
もちろん更なる高速化の余地はありまくりなので
参考までにという事で。